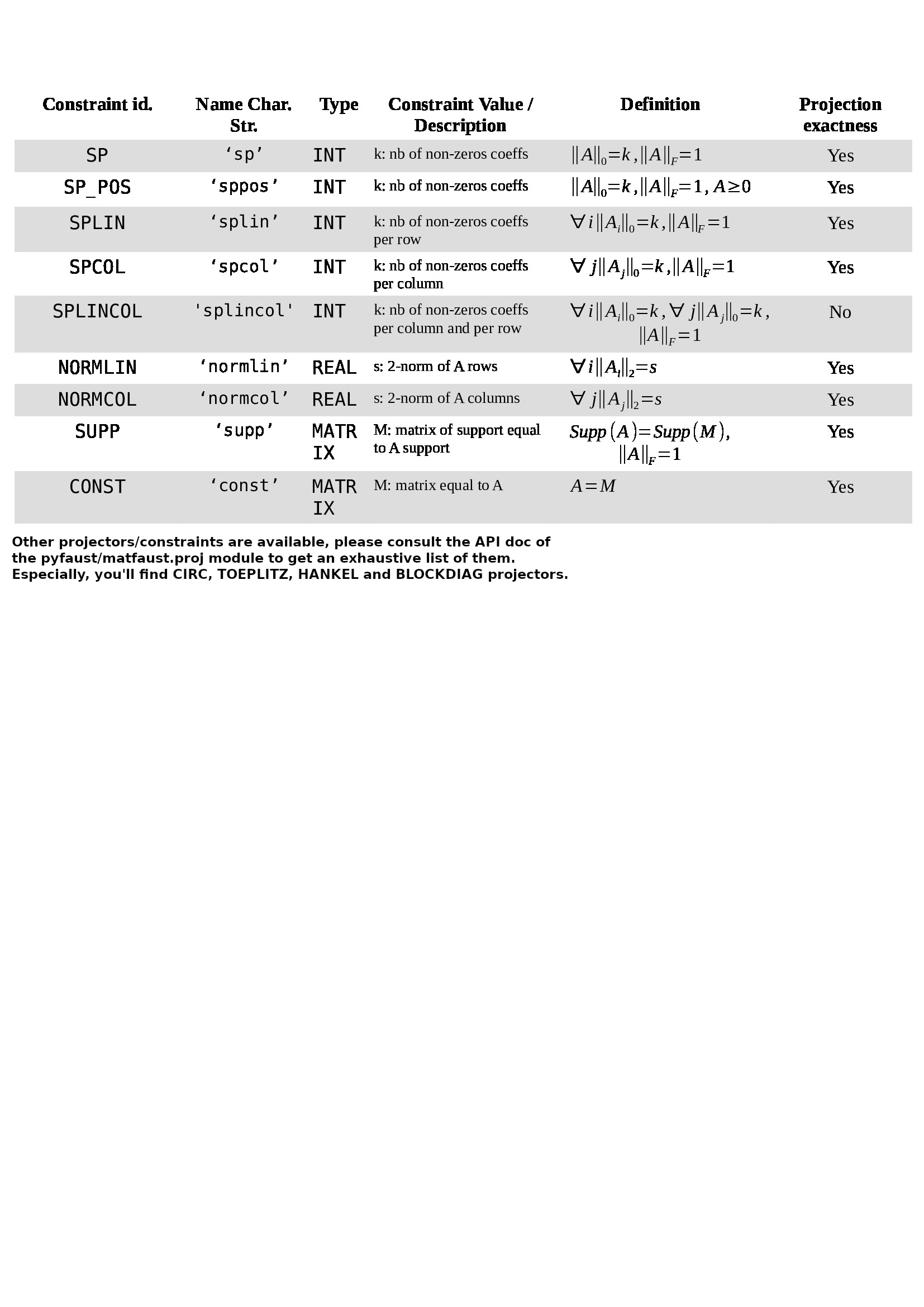
In [1]:
%matplotlib inline
import matplotlib.pyplot as plt
from pyfaust import wht
from numpy.linalg import norm
from numpy.random import rand
# generate a Hadamard Faust of size 32x32
FH = wht(32, normed=False) # normed=False is to avoid column normalization
H = FH.toarray() # the dense matrix version
FH.imshow()
plt.show()






{kind=link}